Today’s problem: LeetCode 242 - Valid Anagram (Easy)
Given two strings s and t, determine whether t is an anagram of s — that is, whether you can rearrange the letters of s to get t.
In the previous article, we discussed the important role that “basic operations” play in problem-solving. This article covers a similar theme: the role of “basic data structures.”
Many people, when grinding LeetCode problems, focus solely on algorithmic tricks while overlooking the role of data structures. In reality, data structures are the foundation of algorithms. Whether it’s stacks and queues that you might consider too simple, or union-find that you might not fully grasp, they are all crucial to the problem-solving approach for many algorithm problems.
This article won’t cover advanced data structures, and today’s problem is quite simple. I’m just using this problem to illustrate a data structure that everyone uses but often overlooks — the counter — to give you a glimpse of the power of basic data structures.
This article will cover:
- Different approaches to the anagram problem
- Applications of the counter data structure
- What basic data structures are
- Related problems
Approaches to the Anagram Problem
Approach 1: Sorting
Anagrams use the same letters, just in a different order. So if we sort the strings, two strings that are anagrams of each other should produce the same sorted result.
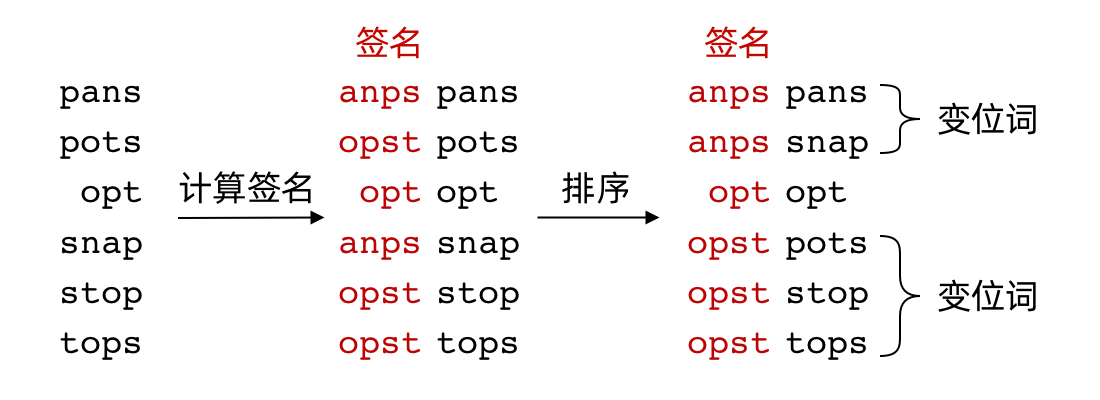
The biggest advantage of the sorting approach is that it can even find all anagrams within a dictionary (a collection of words). We first sort each word to compute its “signature,” then sort by signature — words with the same signature are anagrams of each other. The process is shown below.
However, sorting requires time complexity. If we only need to compare whether two strings are anagrams, counting is actually more efficient.
Approach 2: Counting
If we count the occurrences of each character in the strings, two strings that are anagrams of each other should obviously produce the same count results.

So we simply count the characters in the strings and compare whether the counts for each character are equal.
Language Tips: What data structure should you use for counting in different languages?
In C++, use
unordered_map. C++‘s map automatically creates a default value when you use[]with a non-existent key, which makes counting operations very simple.unordered_map<char, int> counter; for (char c : word) { counter[c]++; }In Java, use
HashMap.HashMap’sgetOrDefaultmethod lets you use a default value when the key doesn’t exist.Map<Character, Integer> counter = new HashMap<>(); for (int i = 0; i < word.length(); i++) { char c = word.charAt(i); counter.put(c, counter.getOrDefault(c, 0) + 1); }In Python, use a dictionary.
counter = {} for c in word: if c not in counter: counter[c] = 0 counter[c] += 1
Here’s the solution code in Python:
def isAnagram(self, s: str, t: str) -> bool:
counter = {}
# Increment count for characters in s
for c in s:
if c not in counter:
counter[c] = 0
counter[c] += 1
# Decrement count for characters in t
for c in t:
if c not in counter:
counter[c] = 0
counter[c] -= 1
for v in counter.values():
if v != 0:
return False
return TrueUsing the Counter Data Structure
You may not know this, but Python’s standard library includes a Counter class specifically designed for this kind of counting work. The Python counting approach above can actually be written using Counter like this:
counter = Counter()
for c in word:
counter[c] += 1Or even more concisely, like this:
counter = Counter(word)This greatly simplifies the code we need to write. Using the Counter class, our solution can even be reduced to a single line:
def isAnagram(self, s: str, t: str) -> bool:
from collections import Counter
return Counter(s) == Counter(t)Amazing! Where language syntax would otherwise force us to write many lines of code, the Counter data structure helps us express our approach in just one line.
That said, in interviews we should still try to use the most common data structures. We just need to know that data structures like Counter exist — their value lies more in helping us clarify our thinking than in simplifying code. Notice that in the code above, even though we use a map for counting, the variable is named counter — that itself is a way of keeping our thinking clear.
Counter and Multiset
Again, I’m not here to promote Python’s advantages. It’s just that when you explore different languages, you discover data structures like Python’s Counter that can simplify your thinking.
However, the counter structure isn’t unique to Python. Many languages have facilities with the same functionality, just under different names. Counter is essentially the mathematical concept of a multiset. A multiset is a variant of a set that allows duplicate elements. When we count the characters in a word and compare whether the counts are the same, we’re really comparing whether the character collections of the words are the same.

Viewed from the multiset perspective, doesn’t this get closer to the essence of the anagram problem?
Many languages have multiset data structures:
- C++ has
std::multiset - Java has Guava’s multiset
For example, in C++ the solution can be written as:
bool isAnagram(string s, string t) {
multiset<char> counter1(s.begin(), s.end());
multiset<char> counter2(t.begin(), t.end());
return counter1 == counter2;
}Java can’t produce concise code even with multiset, so I won’t show it here.
If we understand multiset and know that it can be implemented with a map, we can similarly shield ourselves from the language’s complexity and keep our thinking simple when writing solution code.
The Power of Basic Data Structures
In the previous article, we discussed how basic operations like reverse allow you to think about more content within your limited mental “workbench.” Basic data structures like counter serve a similar purpose — they are an abstraction of data and its operations, allowing you to filter out tedious details and go straight to the heart of the operation.
The first power of basic data structures is that they let us understand the semantics of data structures from a level above syntax.
For example, we actually implement counter using a map, but a map could also store a lookup structure. And for a lookup structure, it can be implemented using either a hash table or a balanced binary tree (HashMap vs. TreeMap in Java).
Data structures can be described both in terms of their low-level implementation (arrays, linked lists, binary trees, hash tables, etc.) and in terms of their high-level properties (stacks, queues, priority queues, search structures, etc.). These high-level properties are the semantics of data structures. A classic example is “heap” and “priority queue.” A heap is a binary tree with element adjustment operations, but when we use it, we don’t care about the internal adjustment details — we only care about the priority queue’s property of moving the smallest element to the front of the queue.
The second power of basic data structures is that they give us more weapons to think about solutions.
In algorithm problems, I believe monotonic stacks and union-find are the best examples of this. Once you understand monotonic stacks, you know that “the next greater element” can be found in time using a monotonic stack, and you can use this known result when solving problems. Even if you need a moment to review the correct implementation of a monotonic stack, you’ve already figured out the basic approach. Once you understand union-find, you know that “maintaining equivalence relations” is a viable strategy. When solving problems, you can naturally think from this angle.
Summary
This article used counter as an example to illustrate the important role of basic data structures. There are quite a few problems that use the counter data structure. Here are some examples:
- 447. Number of Boomerangs
- 594. Longest Harmonious Subsequence
- 621. Task Scheduler
- 1189. Maximum Number of Balloons
Basic data structures may not be as common or intuitive as basic operations, but they are equally useful when summarizing problem-solving approaches. Although the counter data structure discussed in this article is quite simple, it serves as a starting point. Future articles will cover more challenging and impactful data structures commonly seen in algorithm problems, such as monotonic stacks, union-find, and segment trees — stay tuned.