This article introduces a special technique for binary tree problems: operating on adjacent nodes during preorder/inorder/postorder traversal of a binary tree. This approach doesn’t apply to most problems, but for certain specific problems, using this technique can make the solution feel almost effortless.
Do you remember your data structures class, when the professor carefully taught you about preorder, inorder, and postorder traversals of binary trees? Perhaps the moment you see a binary tree, these three traversal orders immediately come to mind. However, once you start grinding problems on LeetCode and work through many binary tree problems, you’ll find that solving these problems seemingly has nothing to do with preorder/inorder/postorder traversals!
That’s right — the most important approach for solving binary tree problems is the subproblem approach, which is exactly what the previous articles on binary trees have been discussing. Many binary tree problems are solved by decomposing them into subproblems and using recursion. With this subproblem approach, we simply let the left and right subtrees recursively complete the computation — whether the left subtree computes first or the right subtree computes first doesn’t matter at all, let alone which traversal order we’re using.
However, the subproblem approach for binary trees isn’t a silver bullet. Sometimes, solving a problem with subproblems can be quite cumbersome. When a problem has special properties, pulling out the preorder/inorder/postorder traversal mindset can be much more effective. This article discusses when it’s appropriate to use the traversal-based approach.
Given a binary tree, determine if it is a valid binary search tree (BST). A BST must satisfy the following properties:
The left subtree of a node contains only nodes with values less than the node’s value;
The right subtree of a node contains only nodes with values greater than the node’s value;
Both the left and right subtrees must also be valid binary search trees.
The “Validate Binary Search Tree” problem can certainly be solved using the subproblem approach. We can define three subproblems: “whether the binary tree is a BST,” “the minimum value of the binary tree,” and “the maximum value of the binary tree.” (As for why these three subproblems — there’s actually a systematic method for this, detailed in the previous article: Binary tree problems too complex? A “three-step” method to solve them!) For each subtree, if the root’s value is less than the left subtree’s maximum or greater than the right subtree’s minimum, then the BST property is violated. The solution code is as follows:
// Note: this code is incomplete, shown only to illustrate the ideaboolean res;public boolean isValidBST(TreeNode root) { res = true; traverse(root); return res;}// Returns two values// Return value 0: the minimum value of the binary tree// Return value 1: the maximum value of the binary treeint[] traverse(TreeNode root) { if (root == null) { return ??; // The boundary case is hard to define } int[] left = traverse(root.left); int[] right = traverse(root.right); if (root.val <= left[1] || root.val >= right[0]) { res = false; } return new int[]{left[0], right[1]};}
There’s a gap in this code: what should the subproblem return when root == null? For an empty subtree, the maximum and minimum values don’t exist, and we’d need special null values to represent the absence of a maximum or minimum. This leads to many additional conditional checks in the code, making it quite cumbersome.
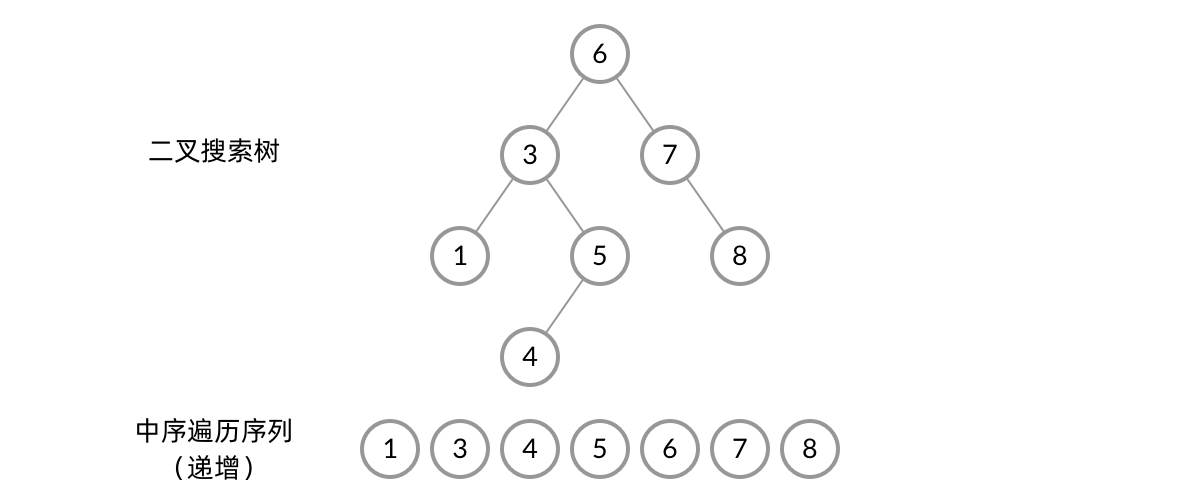
Let’s consider this problem from a different angle. A binary search tree has another property: its inorder traversal sequence is always strictly increasing! We just need to compare each pair of adjacent numbers in the inorder traversal sequence. This avoids dealing with all those special cases in the subproblems.
The inorder traversal sequence of a BST is always strictly increasing
Although we mentioned the inorder traversal “sequence” here, we don’t actually need extra space to store it. During the traversal, we can use a prev variable to keep track of the “previous node” and compare the current node’s value with the previous node’s value each time. This prev variable needs to be a global variable so that it’s not affected by recursive calls.
Ultimately, we can write the following solution:
TreeNode prev; // Global variable: points to the previous node in inorder traversalboolean valid;public boolean isValidBST(TreeNode root) { valid = true; prev = null; traverse(root); return valid;}void traverse(TreeNode curr) { if (curr == null) { return; } traverse(curr.left); // Inorder traversal pattern: place the operation between the two recursive calls if (prev != null && prev.val >= curr.val) { // If the ordering of two adjacent nodes in inorder traversal is wrong, the BST is invalid valid = false; } // Maintain the prev pointer prev = curr; traverse(curr.right);}
The logic of this code is much simpler. At each node we visit, we compare the values of prev and curr. If the previous node’s value is greater than or equal to the current node’s value, the BST is invalid.
The “Adjacent Nodes” Traversal Framework
From the solution code above, we can extract a general framework for binary tree inorder traversal:
TreeNode prev; // prev points to the previous node in inorder traversal// curr points to the current node in inorder traversalvoid traverse(TreeNode curr) { if (curr == null) { return; } traverse(curr.left); if (prev != null) { // Operate on prev and curr here // ... } prev = curr; // Maintain the prev pointer traverse(curr.right);}
This code is essentially a standard binary tree inorder traversal augmented with a prev variable that points to the previous node in the traversal, operating on the prev and curr pair of nodes at each step.
Do you remember the linked list traversal framework from the first article in this series? The linked list traversal framework maintains a prev pointer to the previous node during linked list traversal, and here we’re doing the same thing during binary tree traversal. The difference is that binary tree traversal involves many recursive calls, so the prev pointer needs to be a global variable.
Language tip: Many binary tree solutions require global variables. However, in software development, using global variables has several drawbacks. Instead of using “true” global variables, we can use some special function parameters to achieve the same effect.
In C++, you can use reference-type parameters. A reference parameter can directly modify a variable in the calling function, allowing it to pass through layers of recursive calls.
int foo(TreeNode* root) { int res = 0; traverse(root, res); return res;}void traverse(TreeNode* root, int& res) { res = 1;}
In Java, you can use an array of length 1, since array elements are allocated on the heap and are unaffected by recursive calls.
int foo(TreeNode root) { int[] res = new int[1]; traverse(root, res); return res[0];}void traverse(TreeNode root, int[] res) { res[0] = 1;}
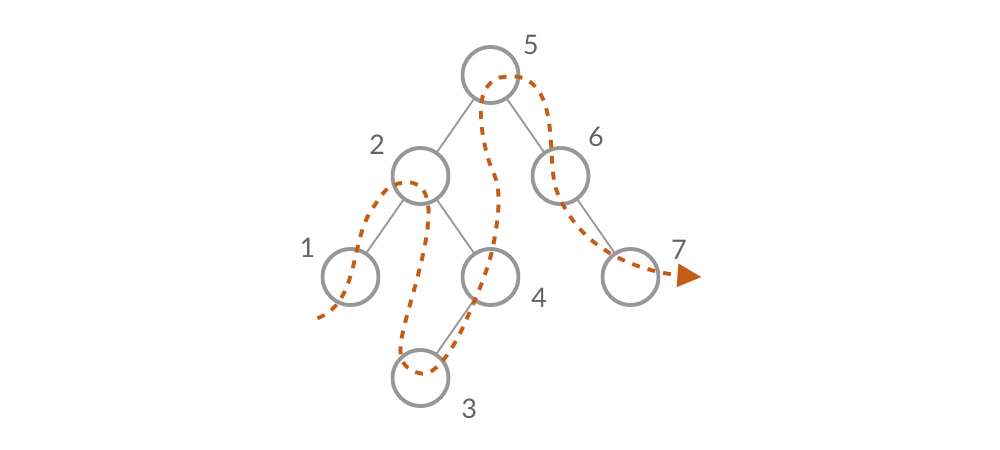
What does it mean to operate on the pair of adjacent nodes prev and curr each time? Taking inorder traversal as an example, imagine a thread passing through each node in the order of the inorder traversal:
Imagine a thread passing through each node in traversal order
This way, at each step of the traversal, prev and curr point to two adjacent nodes on this thread. The “Validate Binary Search Tree” problem is essentially comparing all adjacent nodes along this thread.
This approach of operating on “adjacent nodes” has nothing to do with subproblems. Two nodes that are adjacent in the inorder traversal might be completely unrelated in the binary tree structure — like nodes 4 and 5 in the figure above. It’s precisely because of this property that this method can break free from the constraints of recursion and pull together any two adjacent nodes in the inorder traversal. In certain situations, this approach is more convenient than the subproblem approach.
Convert Binary Tree to Linked List: Linking Adjacent Nodes
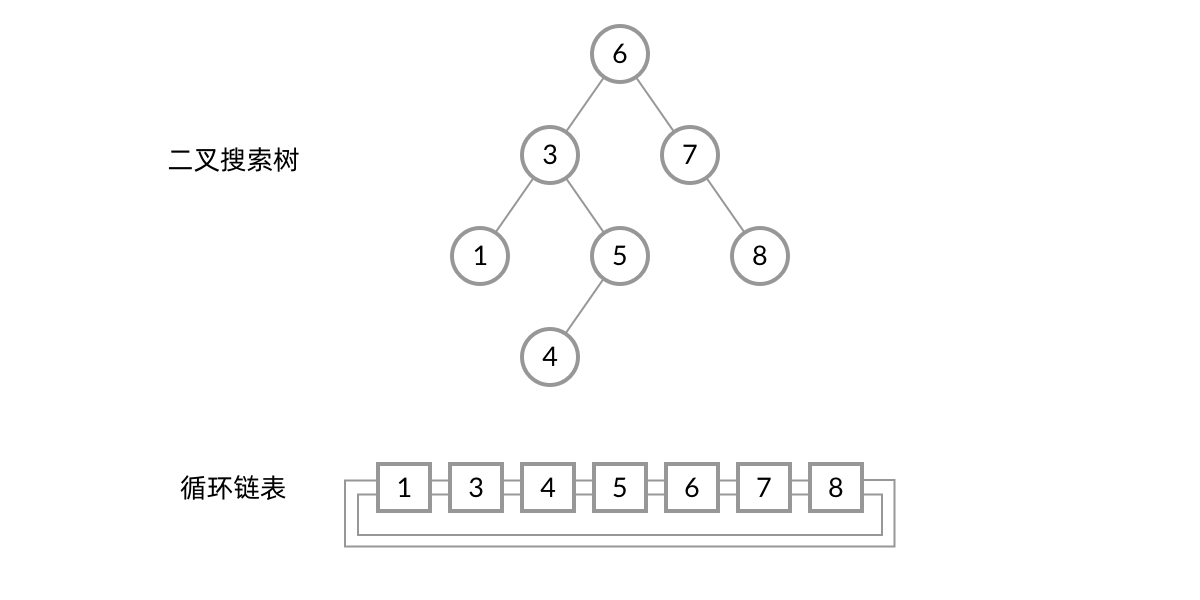
Given a binary search tree, convert it into a sorted circular doubly linked list. The linked list should not use new nodes — instead, use the binary tree’s nodes and adjust their pointers (left pointer serves as the linked list’s prev pointer, right pointer serves as the linked list’s next pointer).
Problem example
Note that although the problem statement mentions a binary search tree, it doesn’t really rely on BST properties. The problem essentially asks us to convert a binary tree into a linked list in inorder traversal order.
Similarly, we could first consider the subproblem approach. We could recursively have the left and right subtrees construct two linked list segments, then concatenate the root node with these two segments. However, concatenating three linked list segments involves many pointer operations, and we’d need to handle the cases where the left or right subtree is empty. Writing this as code would be quite tedious.
Can the adjacent nodes approach make the solution simpler? Let’s revisit the illustration of a thread passing through each node, again in inorder traversal order:
Imagine a thread passing through each node in traversal order
These nodes are also the nodes of the linked list, and the order in which the thread passes through them is exactly the order we need for the linked list. So all we need to do is link adjacent nodes with pointers, and we get the linked list the problem asks for. Yes, the idea is that simple. Here’s the rough pseudocode:
void traverse(Node curr) { if (curr == null) { return; } // Inorder traversal traverse(curr.left); // Traverse left subtree list.append(curr); // (Pseudocode) Append current node to linked list last = curr; // Update last pointer traverse(curr.right); // Traverse right subtree}
As with any linked list problem, we need to check for pointer loss. We notice that after the root node is added to the linked list, its left and right pointers will be modified, so we can no longer access the right subtree via root.right. The fix for pointer loss is simple: save root.left and root.right in temporary variables.
The final solution code is as follows:
Node head; // Head node of the linked listNode last; // Previous node in binary tree traversal, also the tail of the linked listpublic Node treeToDoublyList(Node root) { head = null; last = null; traverse(root); // Convert doubly linked list to circular doubly linked list if (head != null) { head.left = last; last.right = head; } return head;}void traverse(Node curr) { if (curr == null) { return; } // Save the right subtree pointer in advance Node right = curr.right; // Inorder traversal traverse(curr.left); // Append current node to linked list curr.left = null; curr.right = null; if (head == null) { head = curr; } else { curr.left = last; last.right = curr; } last = curr; // Update last pointer traverse(right);}
Two things to note about this code:
During the binary tree traversal, we link nodes into a doubly linked list, but the problem asks for a circular doubly linked list. So at the end, we connect the head and tail nodes.
We actually only need to save the right subtree pointer in advance, because inorder traversal visits the left subtree first before processing the current node. If this were preorder traversal, we’d need to save both the left and right subtree pointers.
Summary
I call this approach of focusing on adjacent nodes during binary tree traversal the “iterative traversal” of a binary tree. When using this approach, we don’t think about the subproblems corresponding to the left and right subtrees — instead, we focus on processing two adjacent nodes in a specific traversal order (preorder/inorder/postorder). This approach doesn’t apply to most problems, but for the right problems, it’s a powerful tool for solving them quickly.
Although both problems in this article use the inorder traversal sequence, this approach works for preorder, inorder, and postorder traversals alike — you just need to adjust the order of “processing the current node” and “recursively calling the two subtrees.”
Here are a few more problems that use this technique — give them a try: