This article will teach you the “prefix sum” algorithmic pattern, enabling you to solve the following LeetCode problems:
- LeetCode 724. Find Pivot Index (Easy)
- LeetCode 560. Subarray Sum Equals K (Medium)
When designing algorithms, time complexity is always a primary concern. We want our algorithms to have the lowest possible time complexity for maximum efficiency. Sometimes, we can reduce an algorithm’s running time by using extra space — this is the space-for-time tradeoff.
Dynamic programming is one class of space-for-time algorithms. By storing the results of all subproblems, dynamic programming avoids redundant computation. The cost is that the DP array takes up extra space.
Prefix sum is another space-for-time technique, except instead of a DP array, we use a “prefix sum array.”
So, what exactly is a prefix sum?
What Is a Prefix Sum?
Let’s start with a simple problem to understand what “prefix sum” is all about:
LeetCode 303. Range Sum Query - Immutable (Easy)
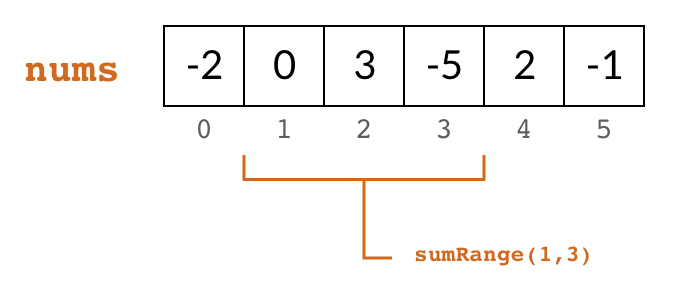
Given an integer array
nums, compute the sum of elements from index to (), inclusive of both endpoints.Example:
Given
nums = [-2, 0, 3, -5, 2, -1], with the sum functionsumRange():sumRange(0, 2) -> 1 sumRange(2, 5) -> -1 sumRange(0, 5) -> -3Notes:
- Assume the array is immutable.
- The
sumRangefunction will be called multiple times.
The solution to this problem is straightforward — the challenge lies in reducing time complexity. Let’s see how different approaches compare in terms of time and space complexity.
Approach 1: Brute Force
With the brute force approach, each call to sumRange uses a for loop to sum the elements from to .
public int sumRange(int i, int j) {
int sum = 0;
for (int k = i; k <= j; k++) {
sum += nums[k];
}
return sum;
}This way, each query (i.e., each call to sumRange) takes time on average. Since sumRange will be called many times, this approach incurs very high time overhead.
Approach 2: Space for Time
When sumRange is called many times, we want to minimize the time per call. If multiple calls to sumRange have the same parameters but still require re-computation, we end up doing a lot of redundant work.
To avoid redundant computation, we can preprocess the array nums by pre-storing the results. We use a 2D array res to store the preprocessed results, where res[i][j] holds the return value of sumRange(i, j).
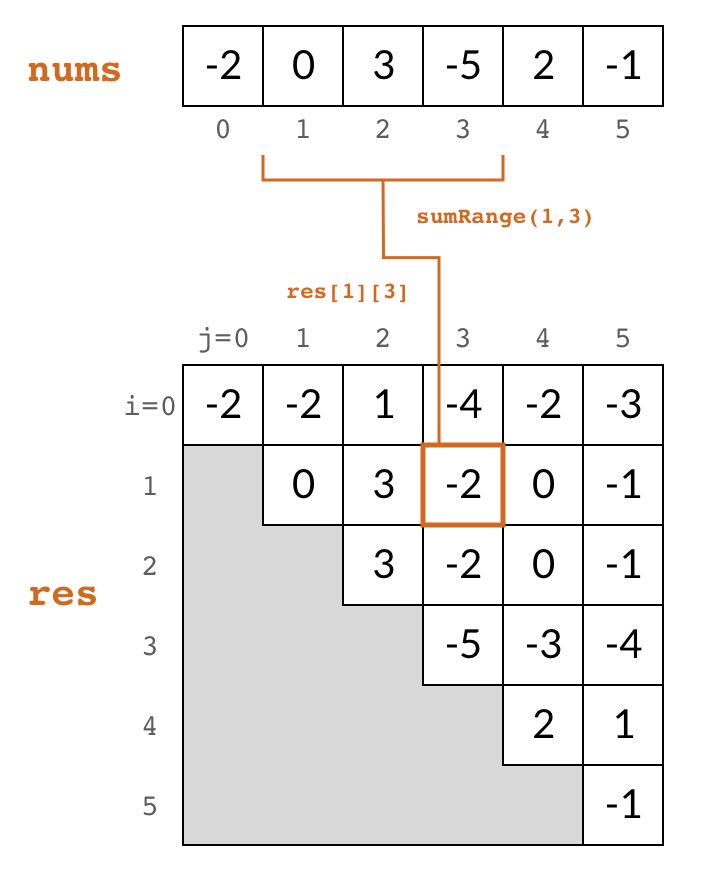
private int[][] res;
// Preprocessing phase
public NumArray(int[] nums) {
int n = nums.length;
res = new int[n][n];
for (int i = 0; i < n; i++) {
int sum = 0;
for (int j = i; j < n; j++) {
sum += nums[j];
res[i][j] = sum;
}
}
}
public int sumRange(int i, int j) {
return res[i][j];
}The complexity analysis for this approach distinguishes between the “preprocessing phase” and the “query phase”:
- Preprocessing phase: time complexity, space complexity;
- Query phase: each query takes time.
Through preprocessing, we achieved a space-for-time tradeoff, reducing the per-query time to a minimum. However, this approach stores all possible results, consuming too much space. Is there a more space-efficient method?
Approach 3: Prefix Sum
The preprocessing in the previous approach is too brute-force and uses too much space. We can use a smarter preprocessing method: prefix sum.
A prefix sum is simply the sum of a consecutive sequence of elements starting from the beginning of the array.
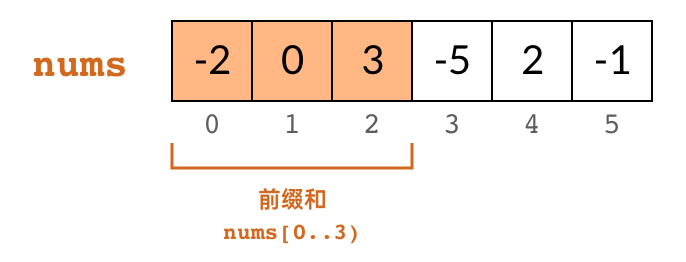
During preprocessing, we compute all prefix sums of the array nums and store them in the array preSum. Here, preSum[k] represents the sum of the first elements of nums (i.e., nums[0..k)), where .
A quick note on notation:
The prefix sum array definition uses a half-open interval (left-closed, right-open). One advantage of this notation is that it makes interval subtraction very easy. For example:
nums[0..j) - nums[0..i)givesnums[i..j). Half-open intervals are also frequently used in sliding window problems.
What makes the prefix sum array so clever?
First, by subtracting two prefix sums, we can quickly compute the sum of elements from to in time:
sumRange(i, j) = preSum[j+1] - preSum[i]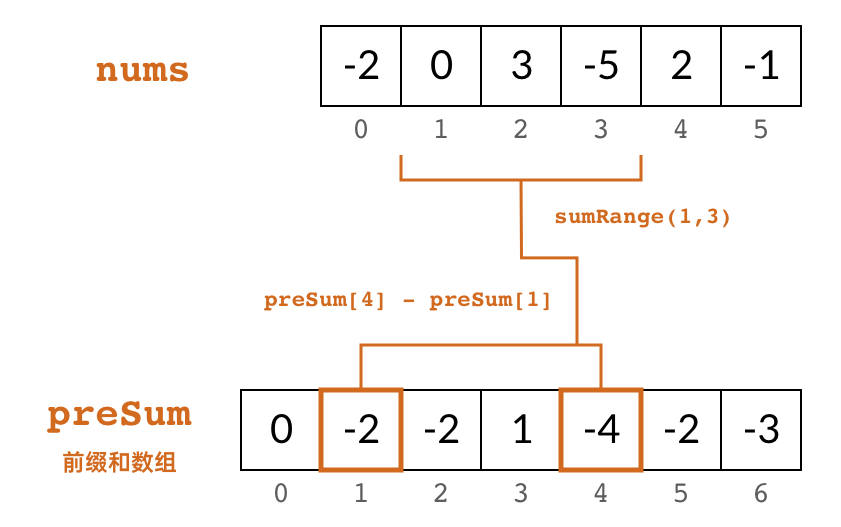
Second, the prefix sum array only takes space, and computing it is simple, requiring only time:
int n = nums.length;
// Compute the prefix sum array
int[] preSum = new int[n+1];
preSum[0] = 0;
for (int i = 0; i < n; i++) {
preSum[i+1] = preSum[i] + nums[i];
}The final solution code is as follows:
class NumArray {
private int[] preSum;
// Preprocessing phase
public NumArray(int[] nums) {
int n = nums.length;
// Compute the prefix sum array
preSum = new int[n+1];
preSum[0] = 0;
for (int i = 0; i < n; i++) {
preSum[i+1] = preSum[i] + nums[i];
}
}
public int sumRange(int i, int j) {
return preSum[j+1] - preSum[i];
}
}Let’s compare the time and space complexity of the three approaches.
| Approach | Space Complexity | Query Time Complexity |
|---|---|---|
| Approach 1: Brute Force | ||
| Approach 2: Brute-Force Space-for-Time | ||
| Approach 3: Prefix Sum |
As we can see, the prefix sum method is characterized by its ability to optimize time complexity while keeping space complexity reasonable. This makes prefix sum a very practical array preprocessing technique.
Applications of Prefix Sum
Now, let’s look at two classic problems to see how prefix sum is applied. These two problems are “Find Pivot Index” and “Subarray Sum Equals K.”
The typical use case for the prefix sum technique is array problems. Whenever you see a problem related to “subarray sums,” consider whether prefix sum can be used to solve it.
Example 1: Find Pivot Index
LeetCode 724. Find Pivot Index (Easy)
Given an integer array
nums, return the pivot index of the array.The “pivot index” is defined as follows: for an element in the array, if the sum of all elements to the left of equals the sum of all elements to the right of , then is the pivot element.
If no pivot index exists, return -1. If there are multiple pivot indices, return the leftmost one.
Example:
Input: nums = [1, 7, 3, 6, 5, 6] Output: 3 Explanation: The sum of elements to the left of index 3 (nums[3] = 6) is (1 + 7 + 3 = 11), which equals the sum of elements to its right (5 + 6 = 11).
We can use a diagram to understand the “pivot element” defined in the problem:
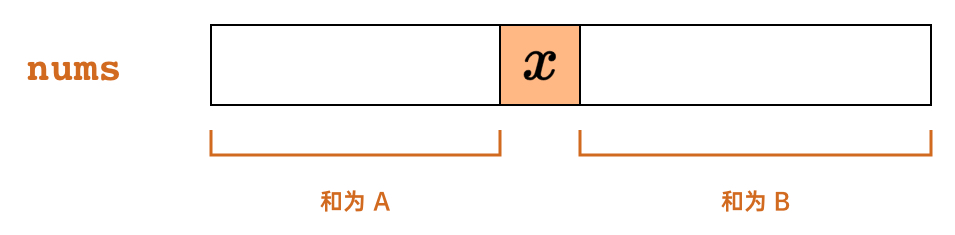
Let be the sum of elements to the left of pivot element , and be the sum of elements to its right. For to be a pivot element, we need .
This problem is concerned with the “sum of elements” on either side of , so we can consider using the prefix sum technique. We notice that the sum of elements to the left of already fits the definition of a prefix sum, so let’s build our approach around .
The sum of elements to the right of can be directly derived from . If we let be the total sum of all elements in the array (which we can compute first), then can be expressed as . Since the pivot element requires , we get:
Simplifying:
In other words, when the prefix sum () and the next element () satisfy the above relationship, element is the pivot element. We can check this relationship as we iteratively compute the prefix sum.
The final solution code is as follows:
public int pivotIndex(int[] nums) {
// First compute the total sum S
int S = 0;
for (int n : nums) {
S += n;
}
int A = 0; // A is the prefix sum
// Iteratively compute the prefix sum
for (int i = 0; i < nums.length; i++) {
int x = nums[i];
if (2 * A + x == S) {
// The relationship is satisfied, x is the pivot element
return i;
}
A += x; // Update the prefix sum
}
return -1;
}The key insight in this problem is recognizing that is a prefix sum, and then applying the prefix sum technique makes the problem straightforward to solve.
Example 2: Subarray Sum Equals K
LeetCode 560. Subarray Sum Equals K (Medium)
Given an integer array
numsand an integer , return the number of contiguous subarrays whose elements sum to .Example:
Input: nums = [1,1,1], k = 2 Output: 2 Explanation: [1,1] and [1,1] are two different cases.
This problem is clearly about “subarray sums,” making it another candidate for the prefix sum technique.
We can first compute all prefix sums, then use them to determine all possible subarray sums. The solution code is as follows:
public int subarraySum(int[] nums, int k) {
int N = nums.length;
// Compute the prefix sum array
// presum[k] represents the sum of nums[0..k)
int[] presum = new int[N+1];
int sum = 0;
for (int i = 0; i < N; i++) {
presum[i] = sum;
sum += nums[i];
}
presum[N] = sum;
// sum of nums[i..j) = sum of nums[0..j) - sum of nums[0..i)
int count = 0;
for (int i = 0; i <= N; i++) {
for (int j = i+1; j <= N; j++) {
// Subtract prefix sums to get the subarray sum
if (presum[j] - presum[i] == k) {
count++;
}
}
}
return count;
}This solution has time complexity and space complexity, which is not optimal.
Although we simplified the subarray sum computation using prefix sums, we still need to enumerate all possible subarrays with a nested loop, resulting in time. To further reduce time complexity, we need to use a hash map technique.
Note:
The hash map technique is not the focus of this article — it is only introduced here to present the optimal solution for this problem. The hash map technique will be covered in detail in a later article.
Let’s take a closer look at the nested loop in the code above:
for (int i = 0; i <= N; i++) {
for (int j = i+1; j <= N; j++) {
// Subtract prefix sums to get the subarray sum
if (presum[j] - presum[i] == k) {
count++;
}
}
}To reduce time complexity, our goal is to transform the nested loop into a single loop.
By rearranging the condition presum[j] - presum[i] == k, we get presum[i] == presum[j] - k. We can then swap the loop order of i and j and rewrite it as:
for (int j = 1; j <= N; j++) {
for (int i = 0; i < j; i++) {
if (presum[i] == presum[j] - k) {
count++;
}
}
}The inner loop is essentially asking “how many values of satisfy presum[i] equals presum[j] - k.” By storing each presum[i] value in a hash map, we can directly look up the count of matching values without needing an inner loop.
We use a hash map to record the frequency of each prefix sum value as we compute them, yielding the following solution:
public int subarraySum(int[] nums, int k) {
// prefix sum -> number of times this prefix sum has appeared
Map<Integer, Integer> presum = new HashMap<>();
// base case: prefix sum 0 appears 1 time
presum.put(0, 1);
int sum = 0; // prefix sum
int res = 0;
for (int n : nums) {
sum += n; // compute prefix sum
// Look up how many sum[i] equal sum[j] - k
if (presum.containsKey(sum - k)) {
res += presum.get(sum - k);
}
// Update the count for sum[j]
if (presum.containsKey(sum)) {
presum.put(sum, presum.get(sum) + 1);
} else {
presum.put(sum, 1);
}
}
return res;
}With this optimization, we’ve reduced the time complexity to while keeping space complexity at .
Summary
This article introduced the prefix sum technique along with two example problems: LeetCode 724. Find Pivot Index and LeetCode 560. Subarray Sum Equals K. Both problems share a common theme: computing subarray sums. Whenever you encounter a problem involving “subarray sums,” it’s always worth considering whether the prefix sum approach applies — you can’t go wrong.
The prefix sum technique is not difficult to master, but it takes some experience to apply it flexibly in different problems. If you haven’t used prefix sum before, I recommend working through these two examples yourself to get a feel for how prefix sum optimizes time complexity.
Prefix sum is a “small technique” that often serves as a local optimization within a larger solution, typically used in combination with other methods. For example, Problem 560 also requires a hash map for further optimization to eliminate unnecessary loops. Hash map techniques will be covered in more detail in upcoming articles.