现在是 2026 年的 3 月份,「Vibe Coding」这个概念已经提出整整一年了。当初人们的设想——只需要用自然语言简单描述需求,AI 便可自动完成——看似已经实现了。现如今的 AI 既智能又勤勉,对于你提出的任何要求都会尽力地去完成。
然而,实际用 AI 来写代码你才会发现,AI 做的东西似乎总是「差那么一点」。差的这一点在哪里呢?在于它并不总是那么可靠。
大部分时间里,AI 可以不知疲倦的干活,并且给出正确的结果。但是,你不知道它哪天就突然写出了有问题的代码,一运行就出现各式各样的 bug。诚然,你可以把问题再扔给 AI,对它咆哮,让它做的时候带点脑子,但是仍然避免不了它一边回答「你说的对」,一边再给你捧上又一个有问题的结果。

即使是号称当前编程能力最强的 Claude Opus 4.6,也经常被人诟病「闷头往前冲」,经常是背景都只了解了个大概就把代码写完了。
那么,AI 编程真的就只能这样一直不靠谱下去吗?在经过一年的 AI 编程实践,以及对于 Agent 原理的深入了解之后,我现在终于可以给出回答:这个问题是可以解决的,真正的秘方在于:给出「验收标准」。
为什么「细致的 Prompt」不能解决问题
在讲解正确的方法之前,我们先来看一个错误的方法:试图给 AI 一个极其细致的 Prompt,来让它避免犯错。
这是一个很自然的思路,我曾经也是使用这种思路:为 AI 指定编程规范,让它给出详尽的方案,讨论详细方案之后再写具体代码。
前几个月流行的 SDD(规范驱动编程),最近流行的 Superpower Skill,都是这种「细致地指导 AI」的产物。它们都是在强调同一件事:别直接写代码,先走流程。 作用是让 AI 不要直接动手写代码,而是走一个需求澄清、头脑风暴、实施计划、代码实现的一整套步骤,希望用这种方式提升 AI 编程的准确率。
乍一看,这种思路完全正确,但是实际用起来,发现它的效果完全没有想象中那样美好。
第一个问题,是对使用者的能力要求很高。
对于复杂的任务,当涉及到我并不是很懂的技术栈时,往往很难评判各种方案之间的优劣,AI 写出来的代码我也很难做到快速把关。再怎么走流程,也很难做到给 AI 细致的指导。最终还是只能寄希望于 AI 不要犯错。
相信对于不懂编程的人来说,情况更是如此。什么编程规范、什么技术方案,一概不知的情况下,「细致地指导 AI」本来就是无法做到的事情。
第二个问题,是 AI 更容易出现幻觉。
走了需求澄清、实施计划这一套流程后,Prompt 会变得非常详细。不过,这些 Prompt 不过是对人原始需求的「展开」。其中很可能存在一些微小的错误。如果缺少人的把关,这些微小的错误就会在一步步的流程中不断放大。到了最后一步,AI 接收到的 Prompt 可能已经和你一开始的需求有了很大的偏差。更何况,如此长的 Prompt,AI 很难完全遵循指令,产生幻觉也是经常有的事情。
编程 Agent 解决问题的真正流程
那么,有没有一种办法,能够让人不需要对 AI 进行细致的指导,或者在没有能力细致指导的情况下,让 AI 正确的完成任务呢?
答案是有的,而且这很符合编程 Agent 的天性。
首先,我们要知道什么是编程 Agent 的天性。
编程 Agent 经过最近一年的大发展,已经收敛到了一个非常稳定的工作流程:工具调用循环。它会不断尝试写代码、不断观察并收集反馈,一轮一轮迭代,直到完成任务。
如果你对这个循环的流程不熟悉,可以回顾下我的这篇文章:
10 分钟讲解 AI Agent(智能体)的底层逻辑,帮助你更好地使用 AI 工具
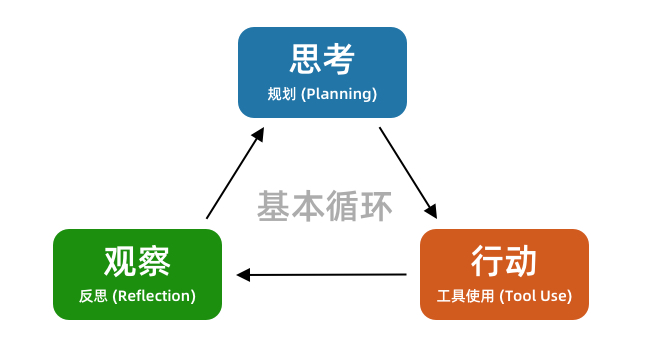
无论是 Cursor、Claude Code,还是 OpenCode,都是遵循着这样一套基本循环。编程 Agent 的原理,决定了它更擅长反馈式的任务,而不是线性的任务。
假如你给 Agent 的目标就是「写完代码」。那么它会走这样一个流程:
写代码 --> 观察代码是否写完 --> 修改代码 --> ...它可能会看看代码文件是否存在,可能会检查下自己的代码,仅此而已。但这是远远不够的:代码看起来没问题,但跑起来可能就有稀奇古怪的 bug。
当你发现了 bug 并让它继续修改的时候,你的反馈实际上加入了整体的循环当中:
[AI]写代码 --> [人]观察是否有bug --> [人]反馈bug --> [AI]修改代码 --> ...有的人的干预,这个循环可以正常进行。但是你会发现自己成了「工具人」—— 永远在机械地帮 AI 验证问题,给它反馈。
说到这里,问题的解法就呼之欲出了。能不能让 AI 自己观察是否有 bug,反馈给自己写代码的流程?这样 AI 就可以自己完成整个循环。
[AI]写代码 --> [AI]观察是否有bug --> [AI]修改代码 --> ...换句话说,我们需要让 AI 能够验证自己代码的效果。
这样一来,编程 Agent 就可以自己走完整个循环流程。即使它一开始写的代码有些问题,也可以通过验证发现问题,并继续修改。修改后,再次验证,如此反复直到验证通过为止。
这样,我们一来不用追求 AI 一次性写对代码,二来不用反复地跟 AI 进行交互。整个过程变得轻松了很多。
如何让 AI 自我验证
那么,有什么方法能让 AI 进行自我验证呢?
这里我给出从简单到复杂的几种办法,适用于不同类型的任务。
方法一:lint 检查
Lint 也叫静态代码检查,这是最基础的代码质量守门员。它能够非常快速地对整个代码库进行扫描,并找出其中的语法错误、拼写问题、变量未定义等不符合规范的地方。
对于 AI 经常犯的幻觉,如「括号没对齐」「删除了代码却没删掉引用」,lint 能够轻易地发现。
就像古法编程时,我们要经常关注 IDE 里的红线黄线一样,lint 就是给 AI 看的「红线」。编程 Agent 应该要能够在写完代码后,立即运行一次 lint,并自动修复这些低级错误。
你可以用这样一段 Prompt 为你的项目配置 lint 检查:
检查项目中是否配置了 lint 检查。如果没有,添加上 lint 检查。如果已有,请与我确认开启的具体 lint 规则。 另外,在 AGENTS.md 中添加这条规则:在每次修改代码后,必须 运行 lint,并保证 lint 检查完全通过。
方法二:集成测试
集成测试可以快速检查系统功能的正确性。例如:调用一个注册接口,观察数据库里是否真的新增了这条用户记录。它不关心具体的代码实现,只关心系统面对一个特定的输入,是否给出了符合预期的输出结果。
当前很多人推崇的 TDD(测试驱动开发)正是这种思路。在 AI 写代码或修改代码之前,先写好具体的测试用例。AI 写完代码后,可以运行这些测试用例观察功能是否正常。
如果你担心让 AI 修改代码时会影响原先的功能,最好的办法就是先写好集成测试,把它作为功能正确的验收标准。
你可以用这样一段 Prompt 为你的项目编写集成测试:
为项目编写集成测试用例,用端到端的方式验证以下功能:A,B,C。 在写好集成测试后,自己运行一遍,直到正确为止。
在修改代码的时候,在 Prompt 添加这样一段话:
在修改代码前,先运行集成测试,确保所有测试通过。 修改代码后,运行集成测试,必须 保证所有集成测试全部通过。 严禁 修改集成测试用例,如果集成测试用例不合理需要修改,请先和我确认。
需要注意的时,这里我说的都是「集成测试」而不是「单元测试」。这是因为集成测试更容易让 AI 从整体功能的角度进行思考,并写出适合验证功能的测试用例。而单元测试往往是针对具体的代码逻辑写的,也很容易过期,整体起到的作用不大。
方法三:浏览器自动化 Playwright
前两种方法(lint 和集成测试),也许不是对于所有系统都适用,也许对于不懂编程的人没那么容易驾驭。
那么这第三种方法:浏览器自动化,便是能够适用各种场景,也适合所有人使用的「大杀器」。
我们前面提到,很多情况下需要人来观察是否有 bug,并给 AI 反馈 bug:
[AI]写代码 --> [人]观察是否有bug --> [人]反馈bug --> [AI]修改代码 --> ...浏览器自动化,便是给 AI 操纵浏览器的能力,让它能够自己打开网页,观察问题,发现问题,再返回头自己修改代码。
现在浏览器自动化最主流的工具是 Playwright,它可以通过 MCP 或者 Skill 的方式集成到你的 Cursor,Claude Code,OpenCode 当中。例如,我的 Cursor 里就安装了 Playwright 工具:

你可以在 Prompt 添加这样一段话:
在功能实现后,本地启动项目并使用 Playwright 访问网页测试功能是否正确。
这时候你就可以看到 AI 不仅会去写代码,还会自己模拟网页上的使用测试功能,并且修正自己测试发现的问题。你再也不需要充当 AI 的人工测试员了。
当然,浏览器自动化可能会让 AI 点击操作很多步骤,token 的消耗会非常大。下一篇文章中我将介绍如何用 Skill 的方式集成 Playwright,节省 token 使用。
总结
如果你也总是被 AI 编程的稳定性所困扰,如果你厌倦了无限次地跟 AI 进行交互,不断之处它写的 bug,那么你一定要尝试本文的三种方法,给你的编程 Agent 配上自我验证的能力,让它自己完成整个循环,写出正确的代码。
请放弃「给 AI 一个完美 Prompt,并让它一次写对」的执念,转而为你的编程 Agent 建立一套反馈闭环。从 lint 检查,集成测试,再到浏览器自动化,无论你添加了哪一种验证方式,都能够让 AI 能够看到自己的代码问题,在迭代修正中达成正确结果。
当这套体系建立起来后,你的编程体验将发生质的改变:不再需要时刻盯着 AI 的进度,不停指出 AI 的 Bug。你只需要给出你的需求,以及验收标准,然后等待 AI 完成任务——当一个甩手掌柜的感觉,谁不喜欢呢?